

University of Science and Technology Beijing
University of Science and Technology Beijing
University of Science and Technology Beijing
University of Science and Technology Beijing
TIP 2024
*First author, †Corresponding author
Controllable 3D-aware scene synthesis seeks to disentangle the various latent codes in the implicit space enabling the generation network to create highly realistic images with 3D consistency. Recent approaches often integrate Neural Radiance Fields with the upsampling method of StyleGAN2, employing Convolutions with style modulation to transform spatial coordinates into frequency domain representations. Our analysis indicates that this approach can give rise to a bubble phenomenon in StyleNeRF. We argue that the style modulation introduces extraneous information into the implicit space, disrupting 3D implicit modeling and degrading image quality. We introduce HomuGAN, incorporating two key improvements. First, we disentangle the style modulation applied to implicit modeling from that utilized for super-resolution, thus alleviating the bubble phenomenon. Second, we introduce Cylindrical Spatial-Constrained Sampling and Parabolic Sampling. The latter sampling method, as an alternative method to the former, specifically contributes to the performance of foreground modeling of vehicles. We evaluate HomuGAN on publicly available datasets, comparing its performance to existing methods. Empirical results demonstrate that our model achieves the best performance, exhibiting relatively outstanding disentanglement capability. Moreover, HomuGAN addresses the training instability problem observed in StyleNeRF and reduces the bubble phenomenon.
The analysis begins with a critical observation in StyleNeRF’s performance: when trained on face datasets (AFHQ and FFHQ), the model produces noticeable distortions in generated images. These artifacts manifest as ‘bubbles’ and ‘ripples’ primarily around facial regions, significantly compromising the generation quality. Feature map analysis reveals that these bubble artifacts correspond to areas of disproportionately high activation in the NeRF component.
In our preliminary experiments, disentangling various 3D control factors on vehicle datasets with large angular rotations proved difficult when employing the common NeRF sampling method for foreground and background modeling. When training the model from scratch on the CompCar dataset, an angle missing phenomenon arises during inference when rotating the vehicle. This phenomenon is also documented in GIRAFFE-HD.

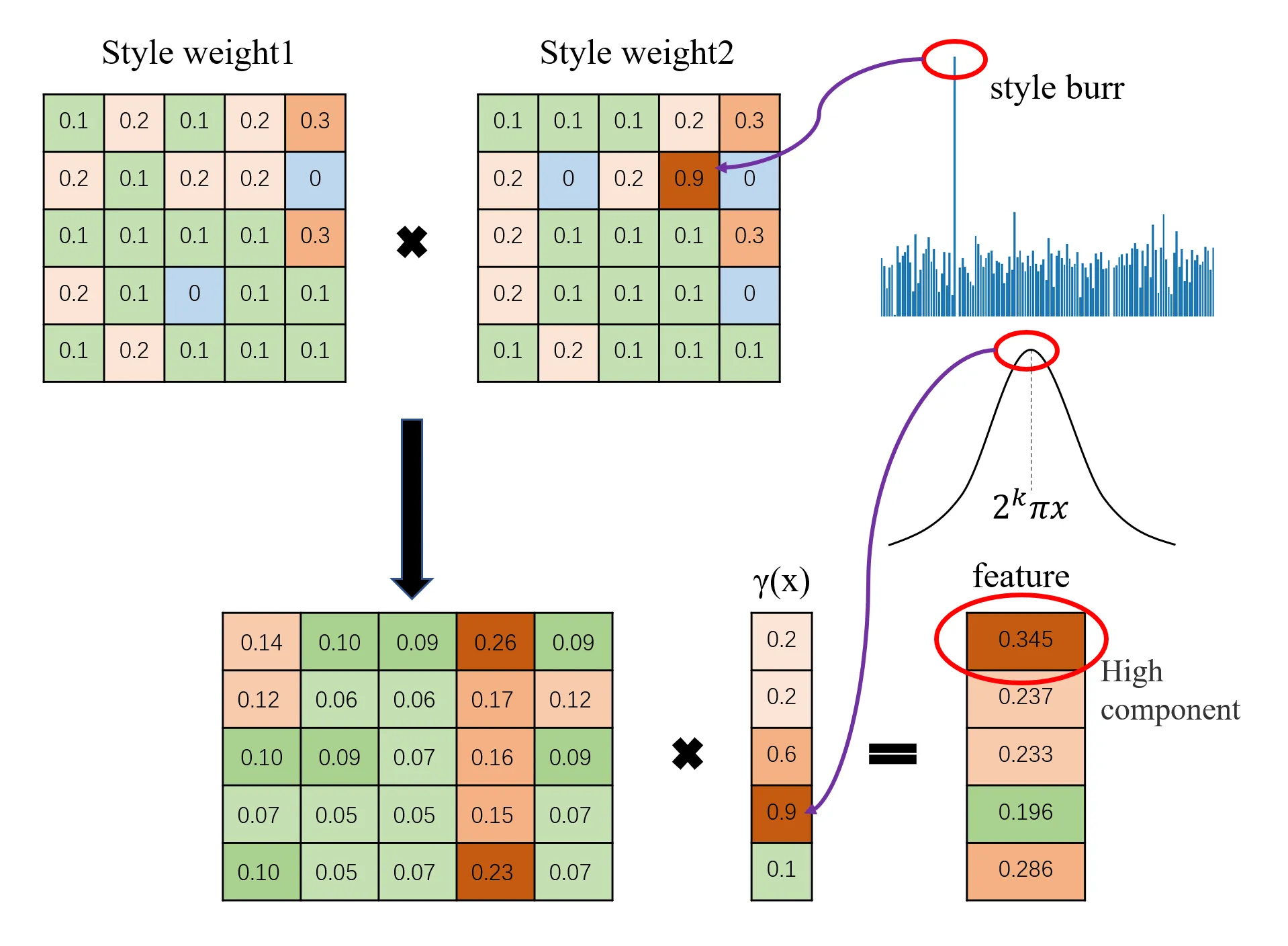
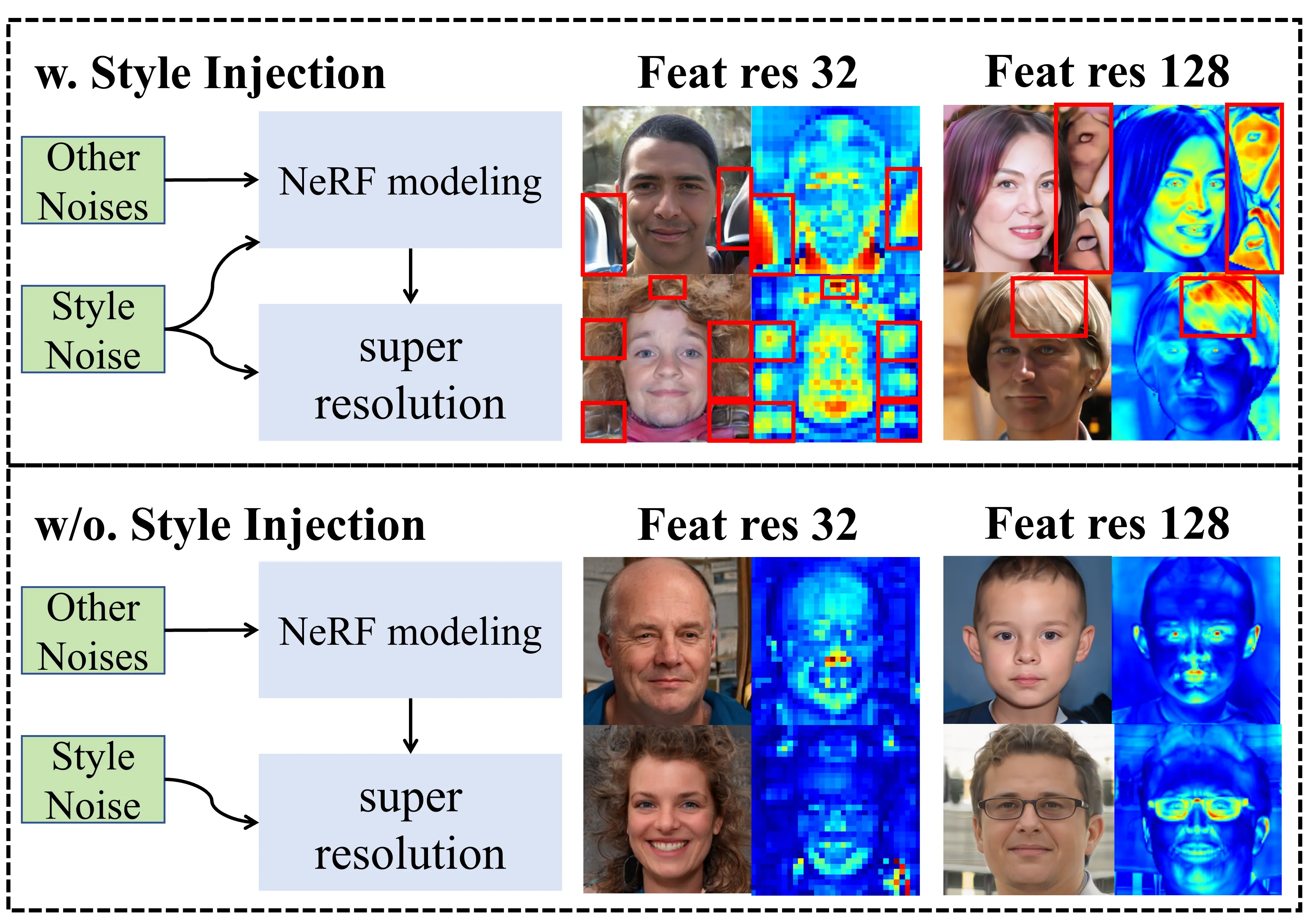
The root cause stems from two main aspects. First, the integration of style code in implicit modeling leads to style burrs and accumulation of larger weights in specific matrix regions, creating localized high-frequency peaks when combined with positional encoding. Second, when sampling points fail to adequately learn scene details, the generator compensates for this frequency deficiency by producing bubbles, either due to the loss of stylized features during volume rendering or the sparse sampling in certain areas hindering high-frequency representation. Additionally, style convolution tends to suppress other noises during implicit modeling, dominating the network output and affecting both shape/texture features and per-pixel style, which may explain StyleNeRF’s inability to train on datasets like CompCar.

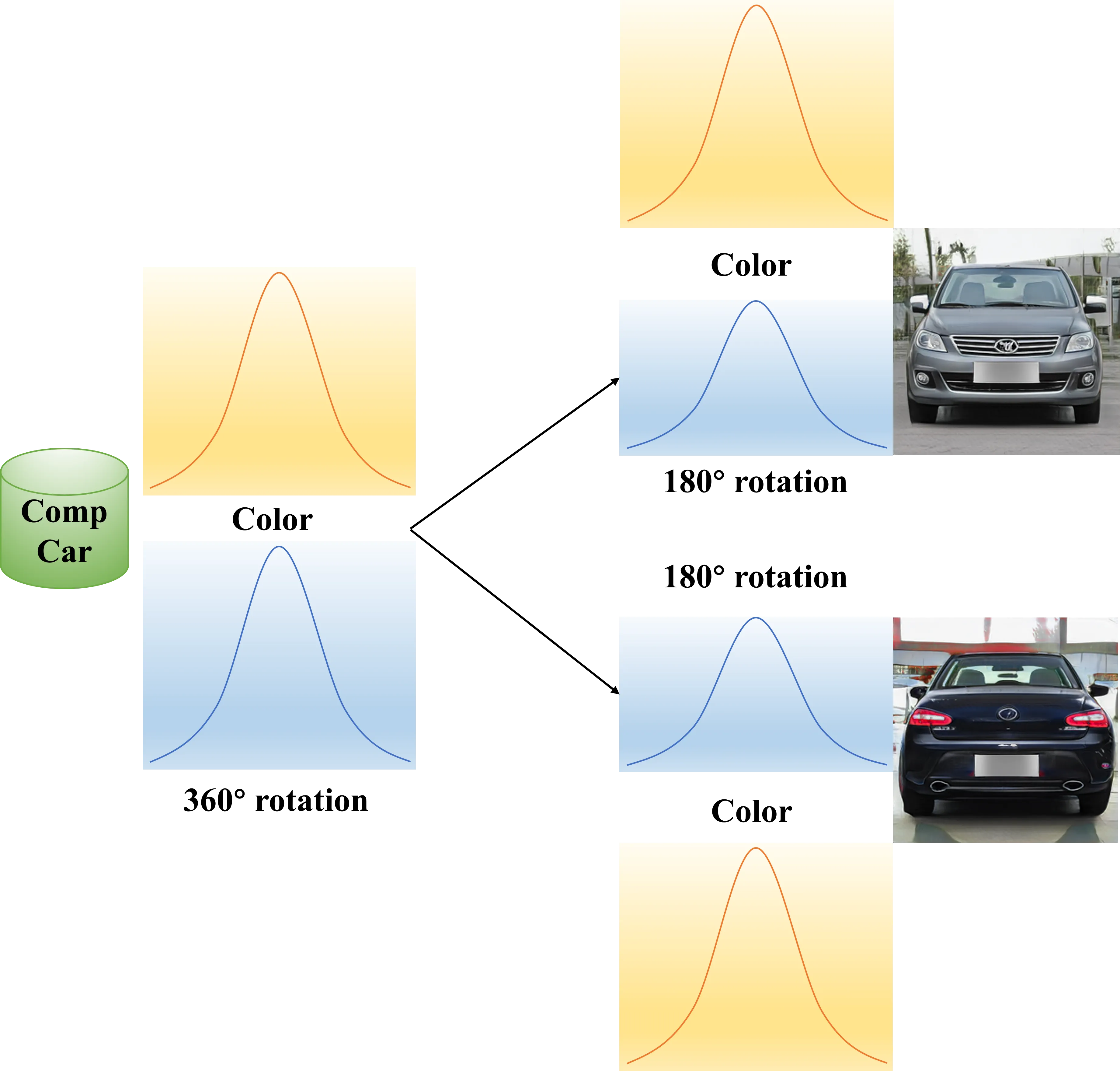
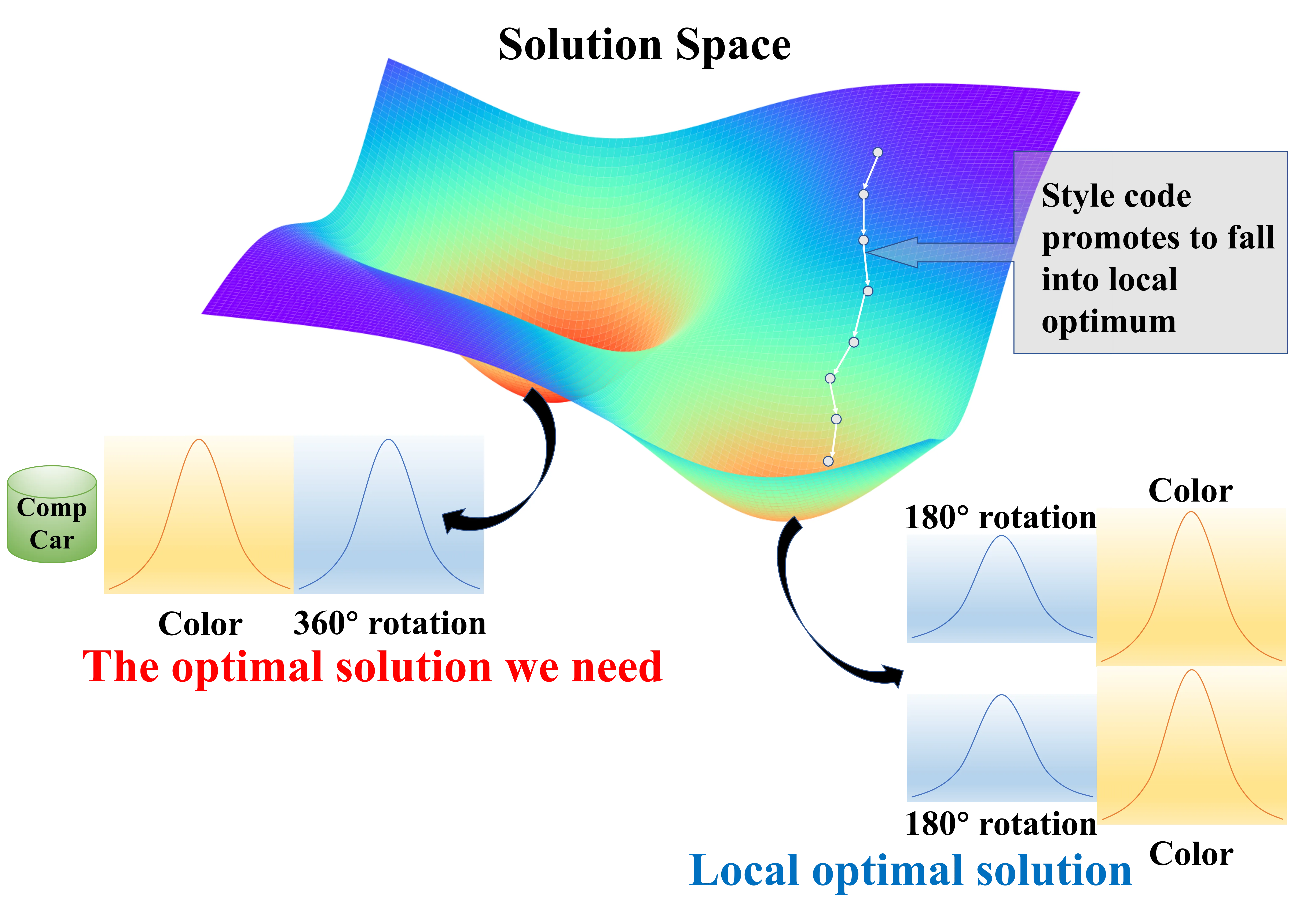
We analyze the missing angles problem in vehicle generation where models can only rotate 180 degrees instead of full 360-degree views. This occurs when the network reaches a local optimal solution. Although the CompCar dataset contains vehicles with 360-degree rotations, the network can still match the original dataset’s distribution by only generating front and rear views. We identify two main causes: first, when style code control becomes too strong, the front and rear views develop independent color distributions; second, when foreground-background decoupling is insufficient, the background collapses onto the foreground, causing the generator to focus solely on foreground fitting. In both cases, the model becomes trapped in this locally optimal solution.
The analysis suggests that decoupling style noise from NeRF is a more suitable strategy for implicit modeling. By removing the style matrix from the equation and preventing the introduction of style information into the NeRF part, the model can avoid generating high feature amplitudes caused by high-frequency style code. This separation also prevents excessive loss of stylistic features during volume rendering, while maintaining a relatively low-frequency implicit space during modeling, which aligns with StyleGAN’s design principles.
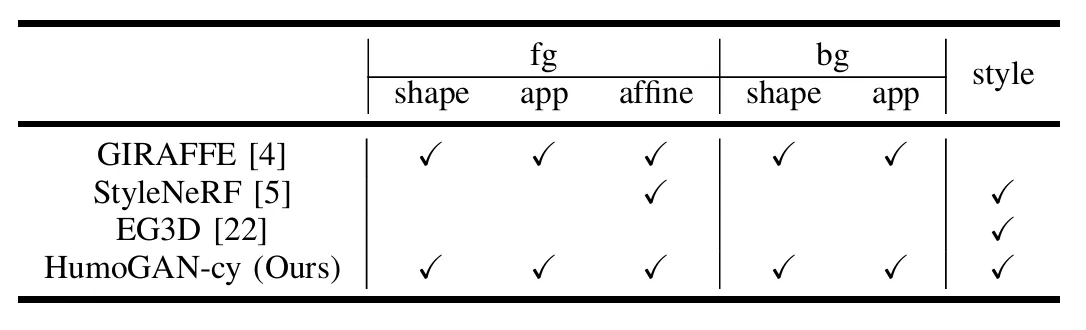
HomuGAN’s architecture and its operational pipeline. The model is designed with versatile input control, accepting five distinct types of noises - foreground shape, foreground texture, background shape, background texture, and style noise - along with a camera matrix. This design enables precise control over the generated object’s posture, style, and shape, achieving effective disentanglement in the generation process.
The architecture processes inputs through four sequential stages. In the point sampling stage, HomuGAN introduces two novel sampling methods: Cylindrical Spatial-Constrained Sampling and Parabolic sampling. The coordinate mapping stage implements a key improvement by disentangling style noise input for both implicit modeling and super-resolution, replacing traditional style convolutions with linear layers. For scene synthesis, the model adopts a direct summation approach for foreground and background features, where background features are scaled by the remaining light content. This method effectively enhances the disentanglement between foreground and background elements. The final super-resolution stage utilizes StyleGAN2’s generator block for progressive upsampling, complemented by a ResNet-based discriminator architecture.
The architecture incorporates several sophisticated design elements, including StyleGAN2’s skip connection implementation and a progressive training mechanism with “fromRGB” modules at various resolutions. The entire pipeline is mathematically formulated to integrate multiple NeRF models with super-resolution modules, creating a robust framework for high-quality 3D-aware image generation. This comprehensive design addresses previous limitations in 3D-aware GANs while maintaining precise control over generation quality and object characteristics.
The method was developed in response to the bubble artifacts problem, which stems from the model’s limited capacity to fit high-frequency information. Through frequency analysis of FFHQ and AFHQ datasets using Haar wavelet decomposition, the research found that high-frequency information concentrates in specific regions - the sides and crown of human heads, and the ears and whiskers of cats. Notably, these high-frequency regions correlate strongly with the locations of bubble artifacts.
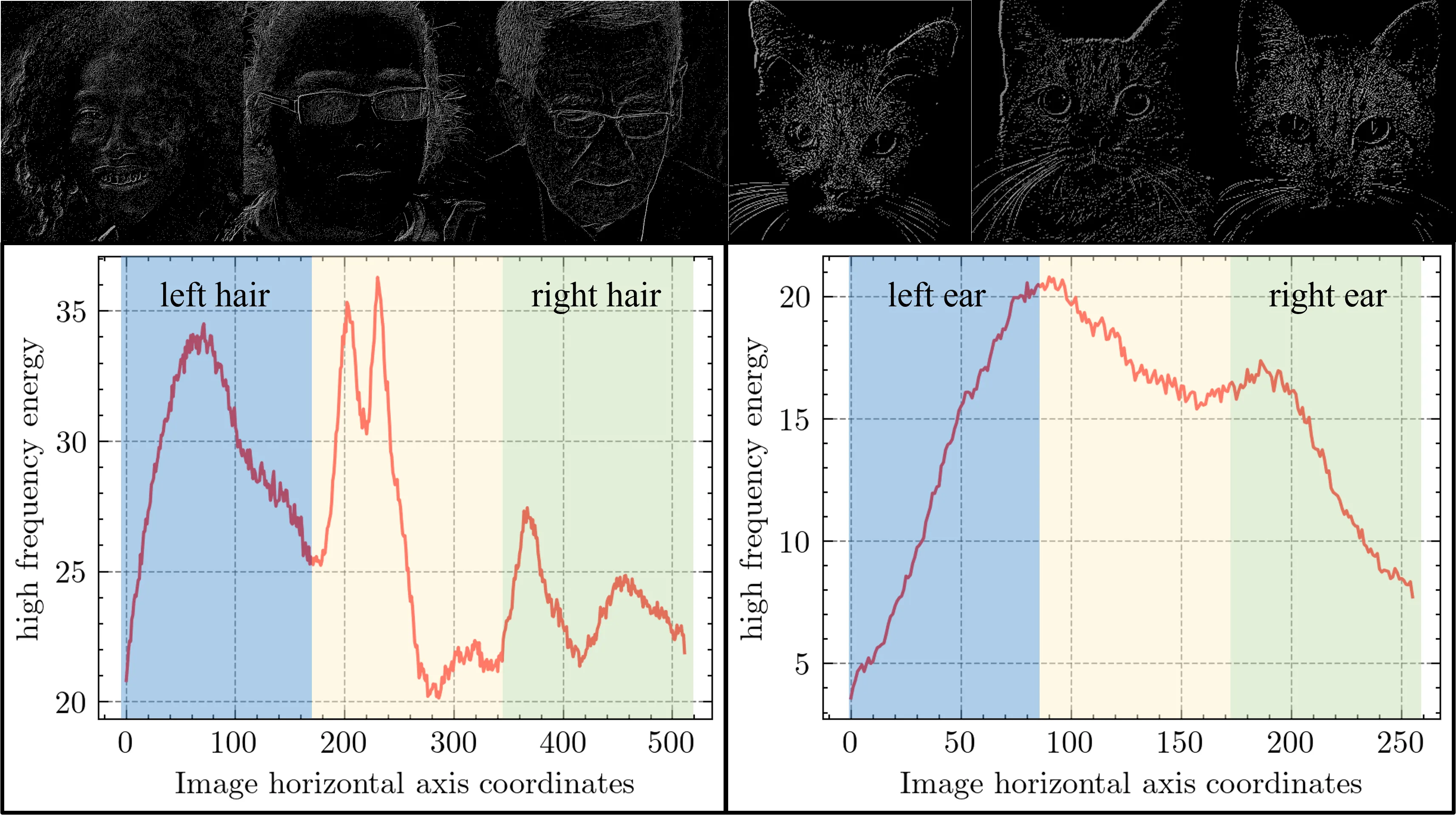
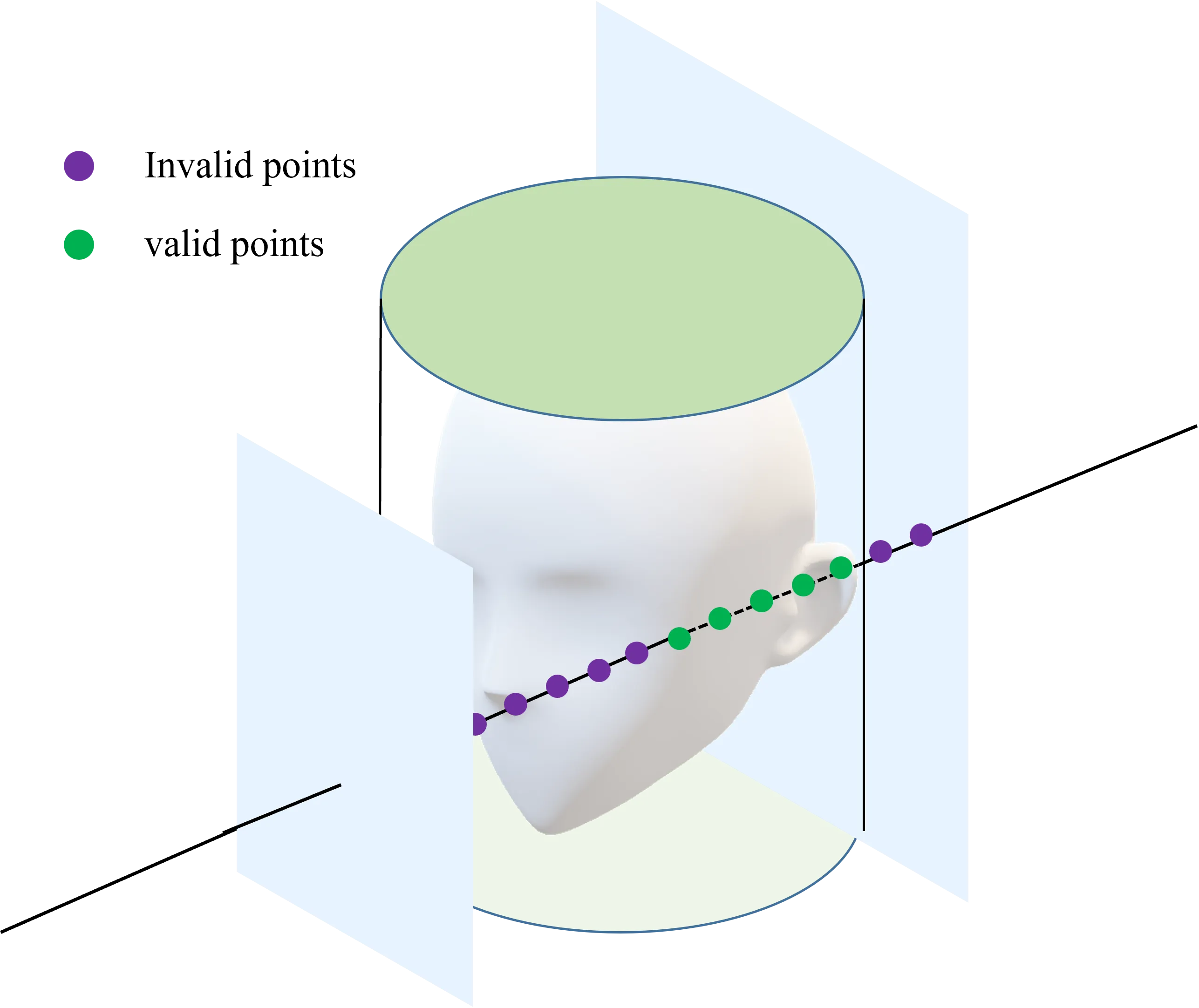
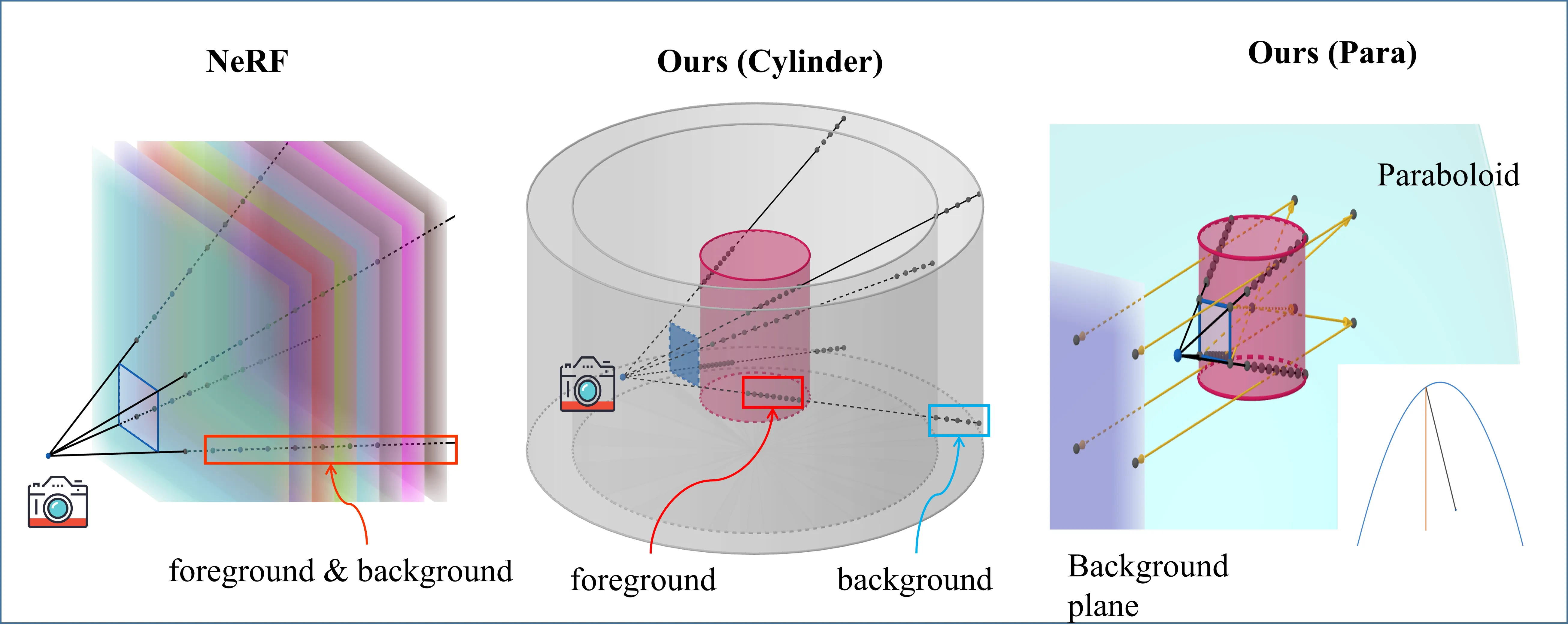
To address this issue, the paper introduces Cylindrical Spatial-Constrained Sampling, which confines sampling points within a cylindrical volume. This approach offers three key advantages: First, it restricts sampling to relevant areas, eliminating unnecessary sampling points outside the region of interest. Second, the cylindrical geometry naturally provides denser sampling near the edges where high-frequency information typically concentrates. Third, it prevents depth-drift artifacts near the edges by avoiding depth modeling in those regions.
The implementation involves two components: foreground sampling within a central cylinder and background sampling between two cylindrical surfaces forming a cinema screen-like structure. The method uses mathematical formulations to determine sampling depth ranges for both foreground and background, with specific considerations for camera position and ray direction. This design effectively improves the model’s ability to capture high-frequency details while maintaining computational efficiency and preventing common artifacts.
We introduce Parabolic Sampling to address the limitations of Cylindrical Spatial-Constrained Sampling in handling 360-degree panoramic scenes, particularly for datasets like CompCar that require complete vehicle views. Our method employs a parabolic surface behind the foreground, with its focal point at the world coordinate origin, to map background rays onto parallel ray groups.
By discarding the x-axis dimension after parabolic reflection, we transform the 3D background modeling into a 2D task, reducing network parameters and computational costs while constraining camera poses to a bounded plane. This design accelerates background representation learning and improves foreground-background separation, making our method particularly efficient for panoramic background generation.
Our experimental results demonstrate comprehensive improvements across multiple aspects. Quantitatively, our model with Cylindrical Spatial-Constrained Sampling achieves superior FID and KID scores on FFHQ, AFHQv2, and CompCar datasets at various resolutions, outperforming both camera-free and foreground-background disentangled models. While Parabolic Sampling shows slightly lower performance, it still exceeds baselines for CompCar and AFHQ, particularly excelling in vehicle modeling.


The results demonstrate the capacity of our model to produce low anomaly outputs, as measured by both manual screening and automated anomaly evaluation.This suggests that samples from our model exhibit a relatively low incidence of bubble artifacts or failed samples.
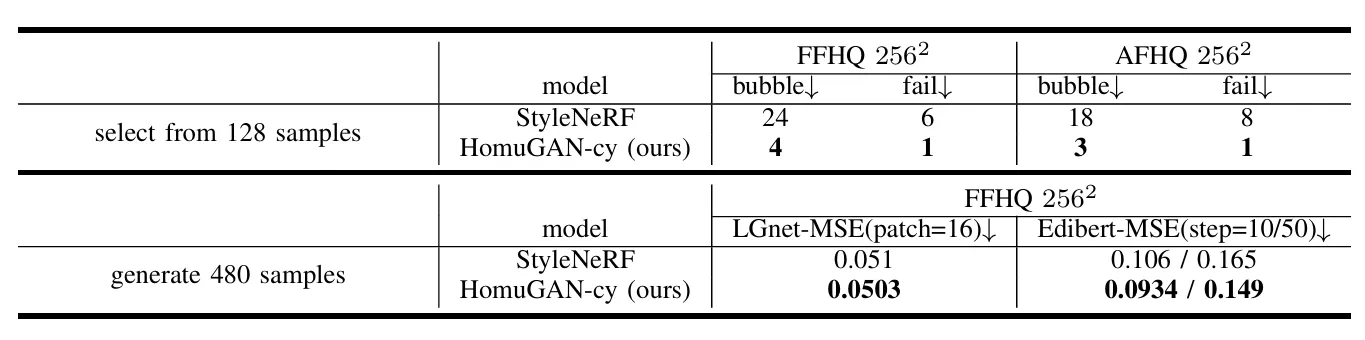
We evaluate our model’s effectiveness through multiple metrics. Manual screening and automated evaluation confirm that our model significantly reduces bubble artifacts and anomalies in generated samples. To assess 3D consistency, we employ ArcFace for face similarity measurement between different views and Deep3DFaceRecon for pose accuracy evaluation. Our method achieves the highest 3D consistency among models that support foreground-background disentanglement and operate without camera annotations. We further validate our results using COLMAP reconstruction from multiple viewpoints, demonstrating that our model consistently produces high-quality, 3D-consistent images with minimal artifacts.

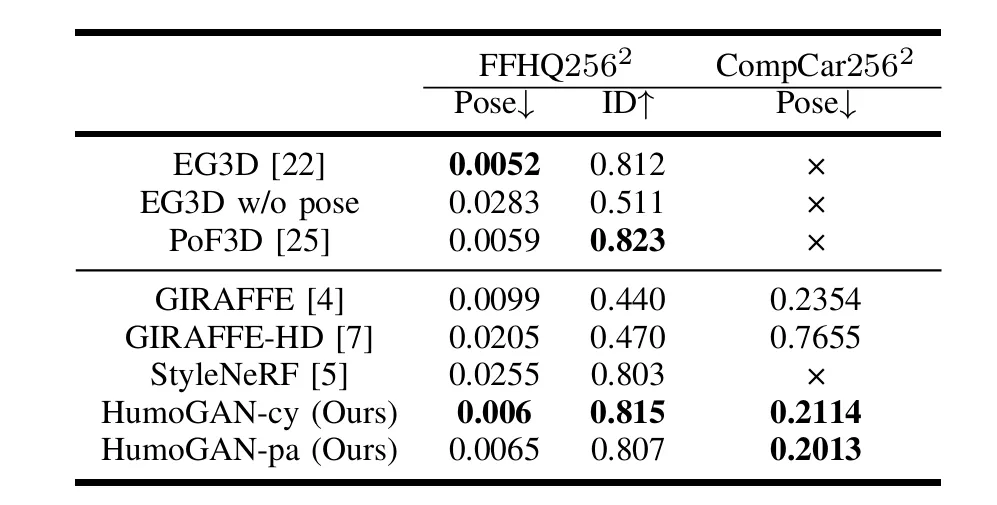

We evaluate the controllability of different models by varying noise inputs. While StyleNeRF exhibits a deactivation phenomenon where only style noise affects the output (due to its style modulation in implicit modeling), our model maintains effective control over all noise types. In comparison, GIRAFFE shows strong foreground-background control but lacks style control, and EG3D relies solely on style noise without foreground-background differentiation. Our model achieves balanced control across all aspects, demonstrating superior controllability over existing approaches.

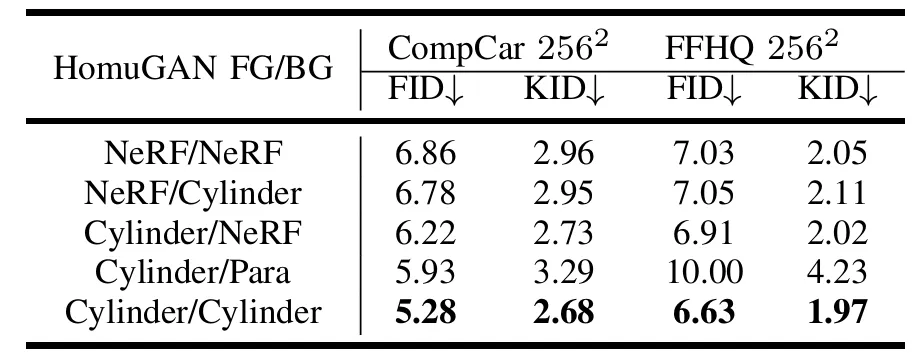
Experimental findings indicate that the original NeRF sampling method is suboptimal for producing high-fidelity images. In contrast, our proposed method, employing Cylinder-based sampling for both foreground and background, yields optimal performance. While Para demonstrates similar results to Cylindrical Spatial-Constrained Sampling on the CompCar dataset and exhibits strong foreground vehicle modeling (as evaluated by three-dimensional consistency metrics), it introduces background flickering. Moreover, parabolic sampling significantly reduces performance on the FFHQ dataset. Considering these performance trade-offs, we classify this modeling strategy as an optional optimization.
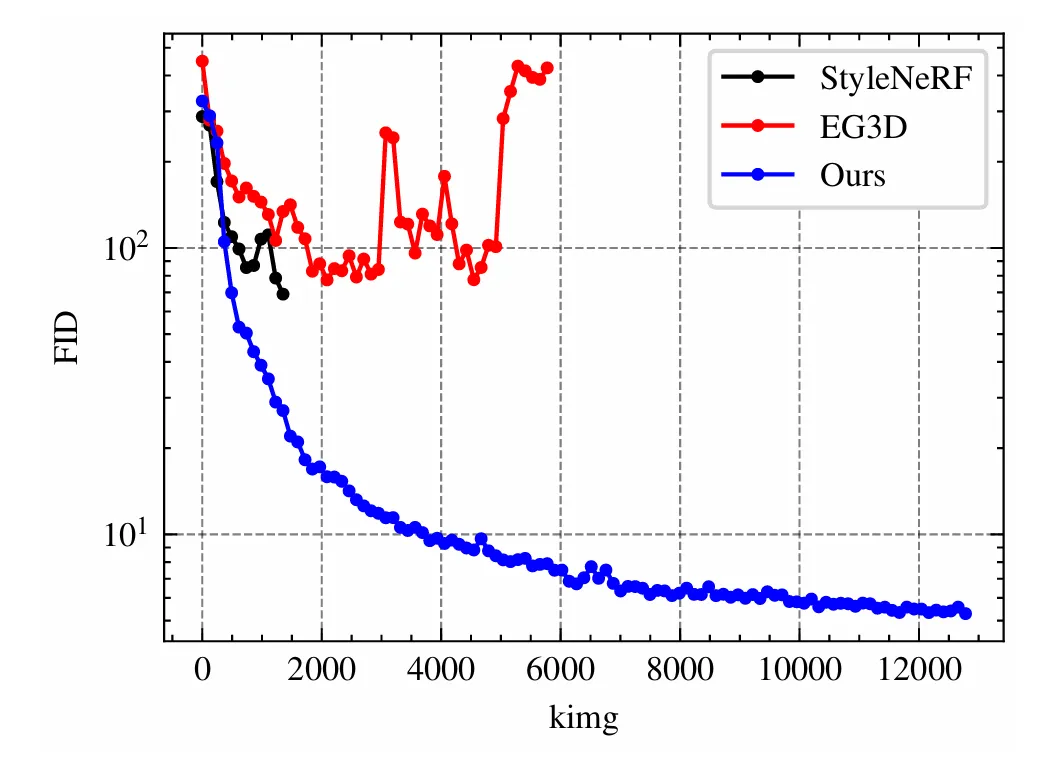
A comparison of StyleNeRF and EG3D with our model indicates differences in FID fluctuation throughout training on CompCar. As Figure illustrates, our model not only exhibits superior FID scores but also demonstrates a relatively consistent and rapid convergence. Our model can train stably on CompCar without the occurrence of mode collaps.
To validate our design choice of removing style noise, we conducted a comparative experiment by reintroducing style noise into our model’s architecture. Feature map visualization and anomaly metrics demonstrate that the presence of style noise generates unwanted high-frequency features and increases artifacts, confirming the effectiveness of our style noise removal strategy.

@ARTICLE{10816358,
author={Yu, Haochen and Gong, Weixi and Chen, Jiansheng and Ma, Huimin},
journal={IEEE Transactions on Image Processing},
title={HomuGAN: A 3D-aware GAN with the Method of Cylindrical Spatial-Constrained Sampling},
year={2024},
volume={},
number={},
pages={1-1},
keywords={Three-dimensional displays;Neural radiance field;Solid modeling;Superresolution;Generative adversarial networks;Faces;Training;Modulation;Feature extraction;Cameras;Implicit modeling;3D-aware synthesis;Neural radiance fields sampling},
doi={10.1109/TIP.2024.3520423}
}